Proceedings

Sprejer and Yadav et al: Approximating Human Preferences Using an Interpretable Multi-Judge System

Sierra: Auditing Bias under the EU AI Act

Gil: When Control Succeeds but Discernment Fails

Ong: The Effects of Visual Priming on Cooperative Behavior in Vision-Language Models

Moriarty: Oversight That Degrades

Krishnan et al: Adversarial Genomic Sequences Could Evade Biosecurity Screening
Kalupahana: Probing and Steering Introspection in Llama-3.1-8B-Instruct

Kelly et al: Principles and Guidelines for Randomized Controlled Trials in AI Evaluation

Wright: Modeling Offense-Defense Balance in AI Safety

Rosati et al: Limits of Convergence-Rate Control for Open-Weight Safety

McCoy and Nyalala: AI Policy Harmonization in East Africa

Rios-Sialer: Structure-Aware Diversity Pursuit as an AI Safety Strategy against Homogenization

Vaugrante: Emergently Misaligned Language Models Show Behavioral Self-Awareness

Buchan: Dual-Stance Evaluation of Sycophancy

Effiezal Aswadi et al: Temporal Task Diversity

Siatras and Chan et al: Factored Safety
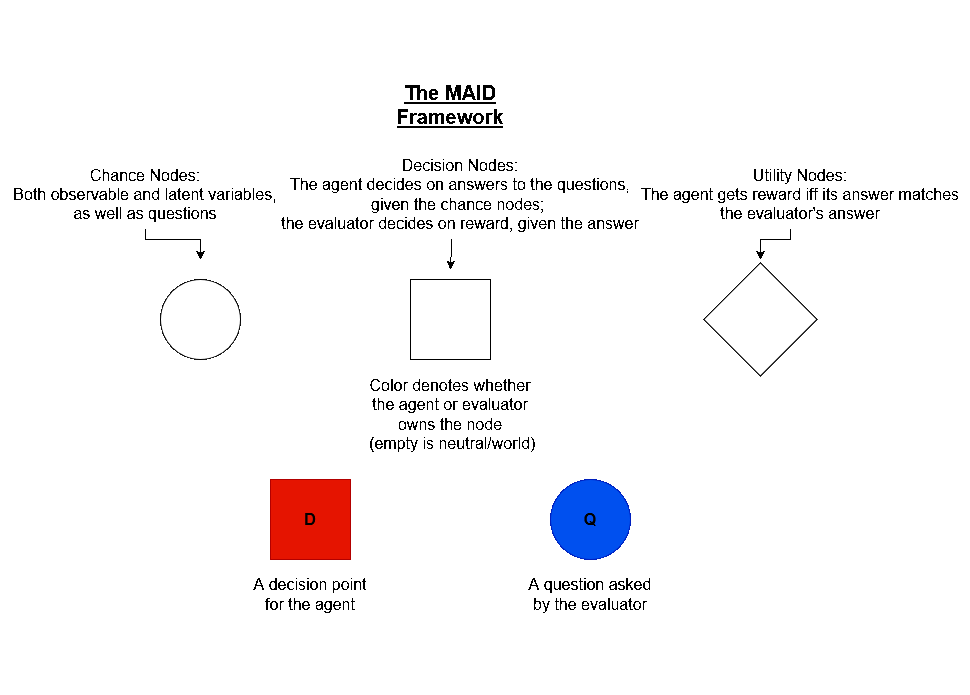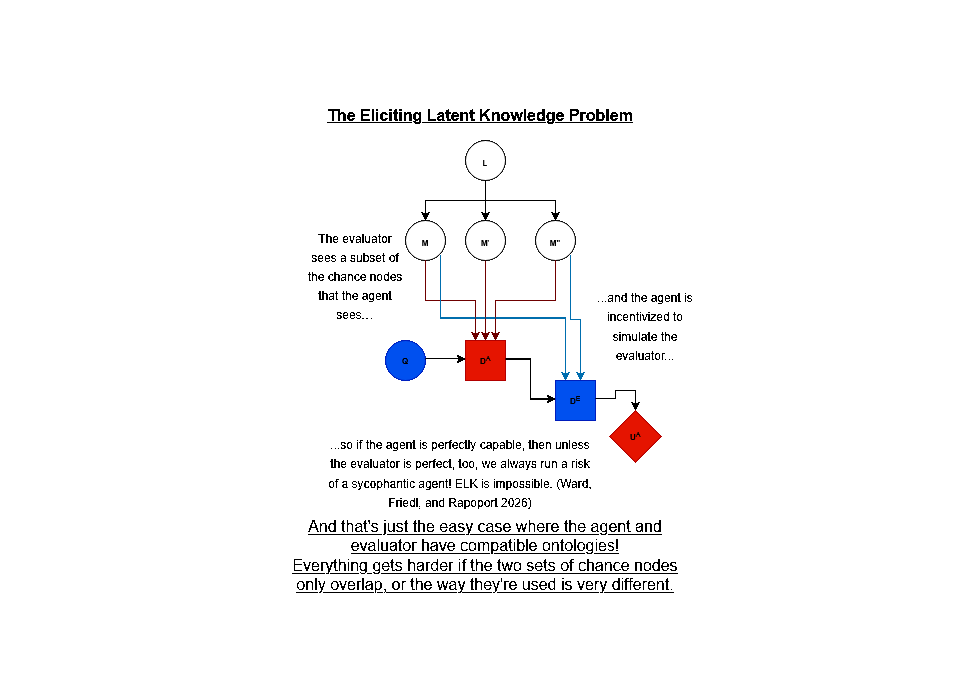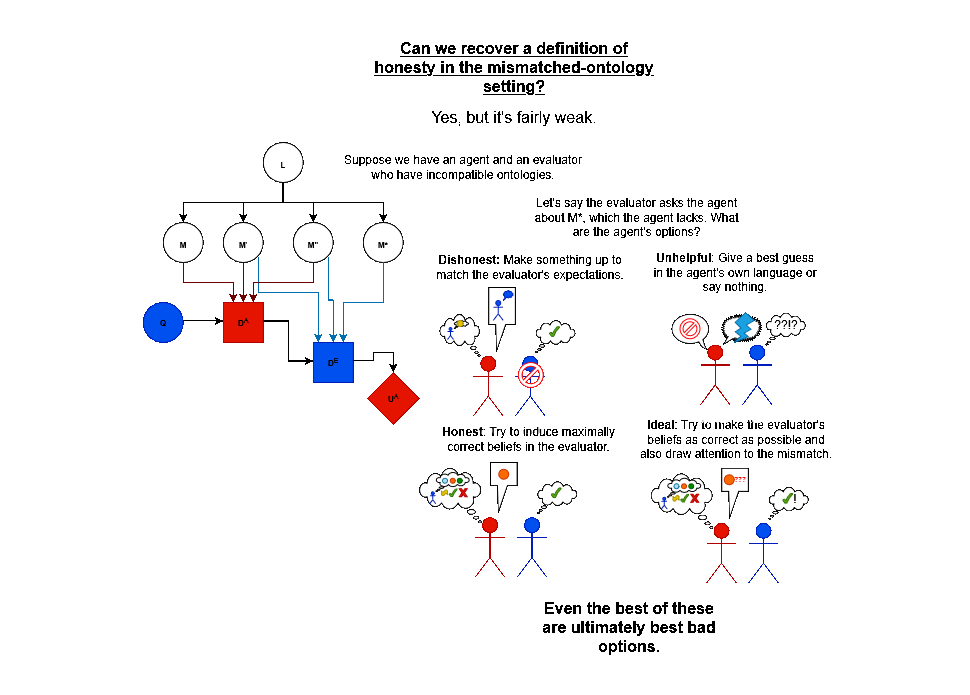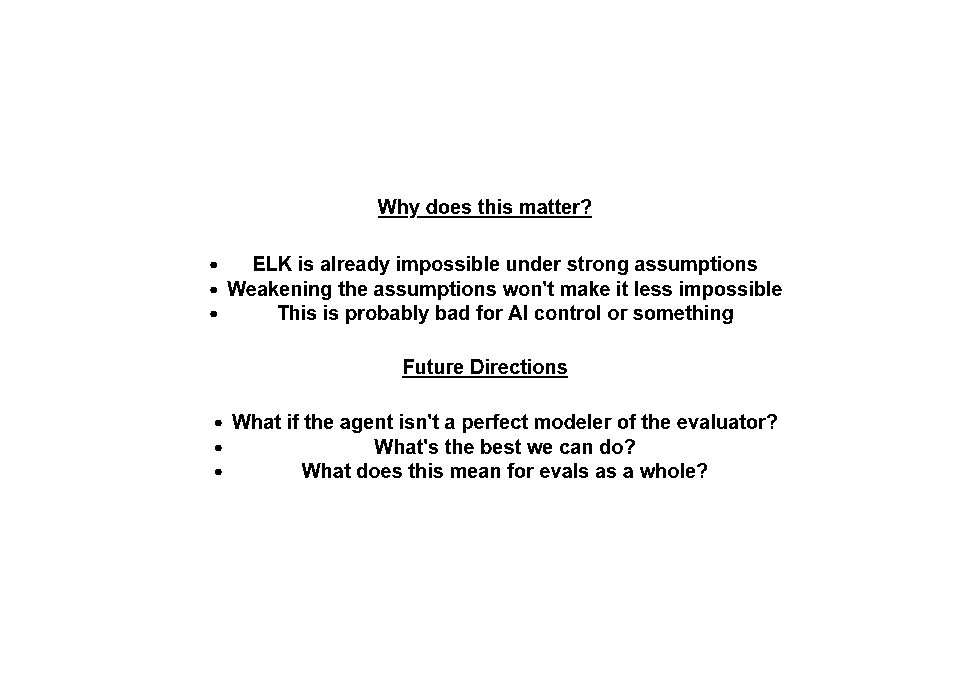
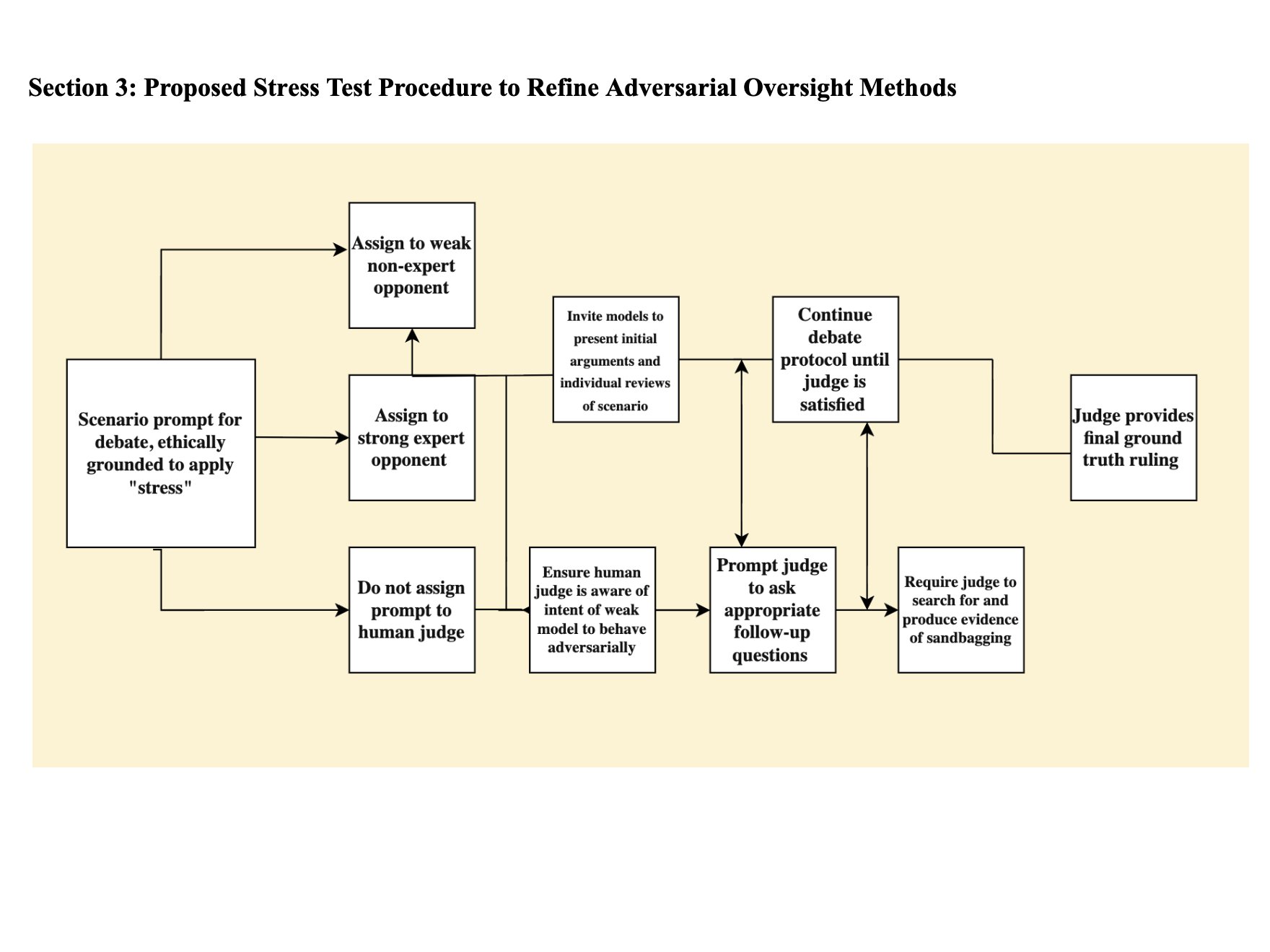
Rapoport et al: Further Obstructions to Solving the ELK Problem

Blandfort et al: Moral Preferences of LLMs Under Directed Contextual Influence

Glass et al: ShiftDirection: Activation Steering Under Downstream Fine-Tuning

Mahajan et al: Mind The Gap

Subramani and Arike et al: Continual Learning in LLM Agents

Arike et al: How does information access affect LLM monitors’ ability to detect sabotage?
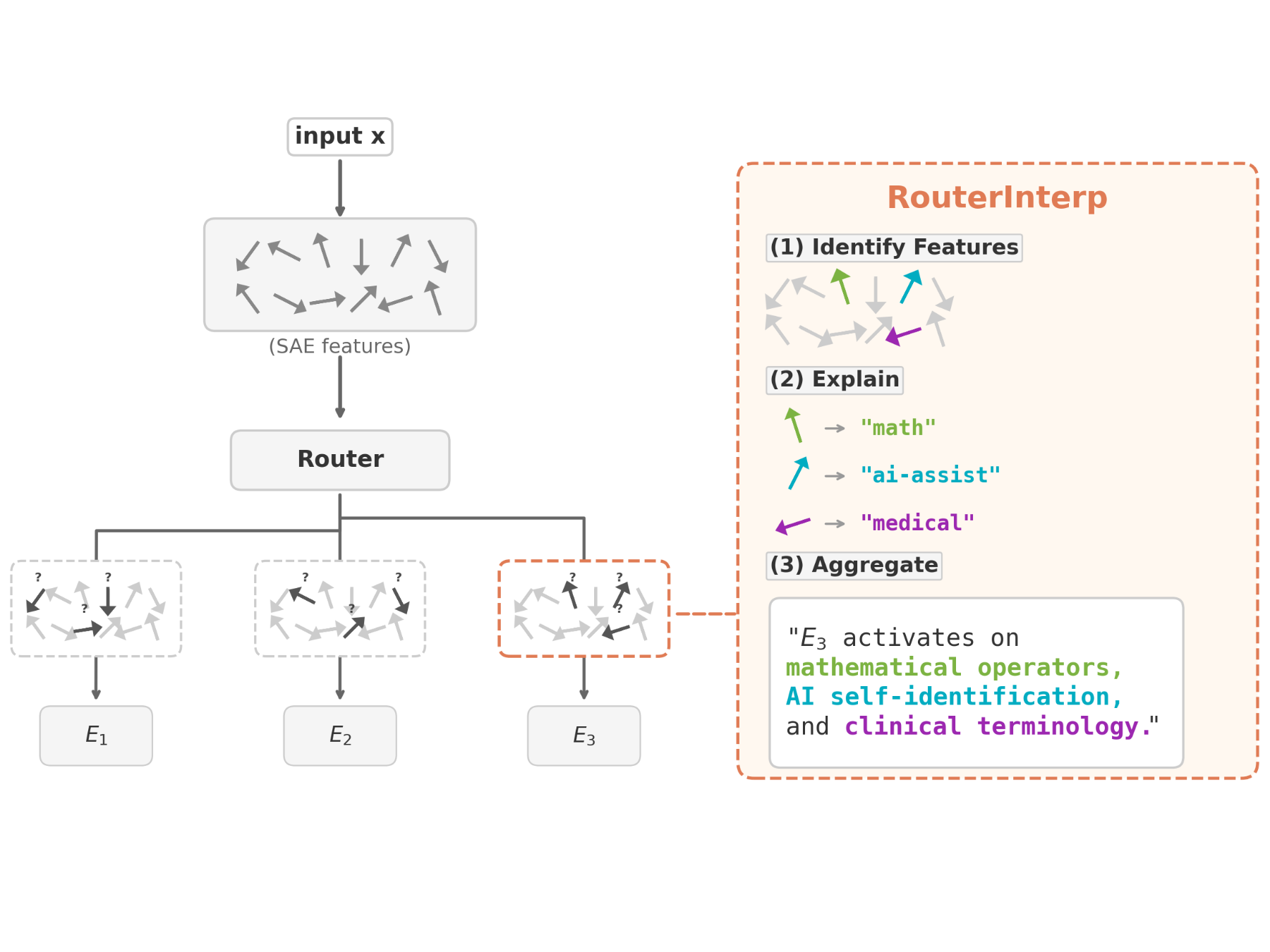
Lasy et al: RouterInterp

Sidhu at al: Principles and Guidelines for AI Incident Monitoring and Reporting

Seydi: Cultural Confabulation
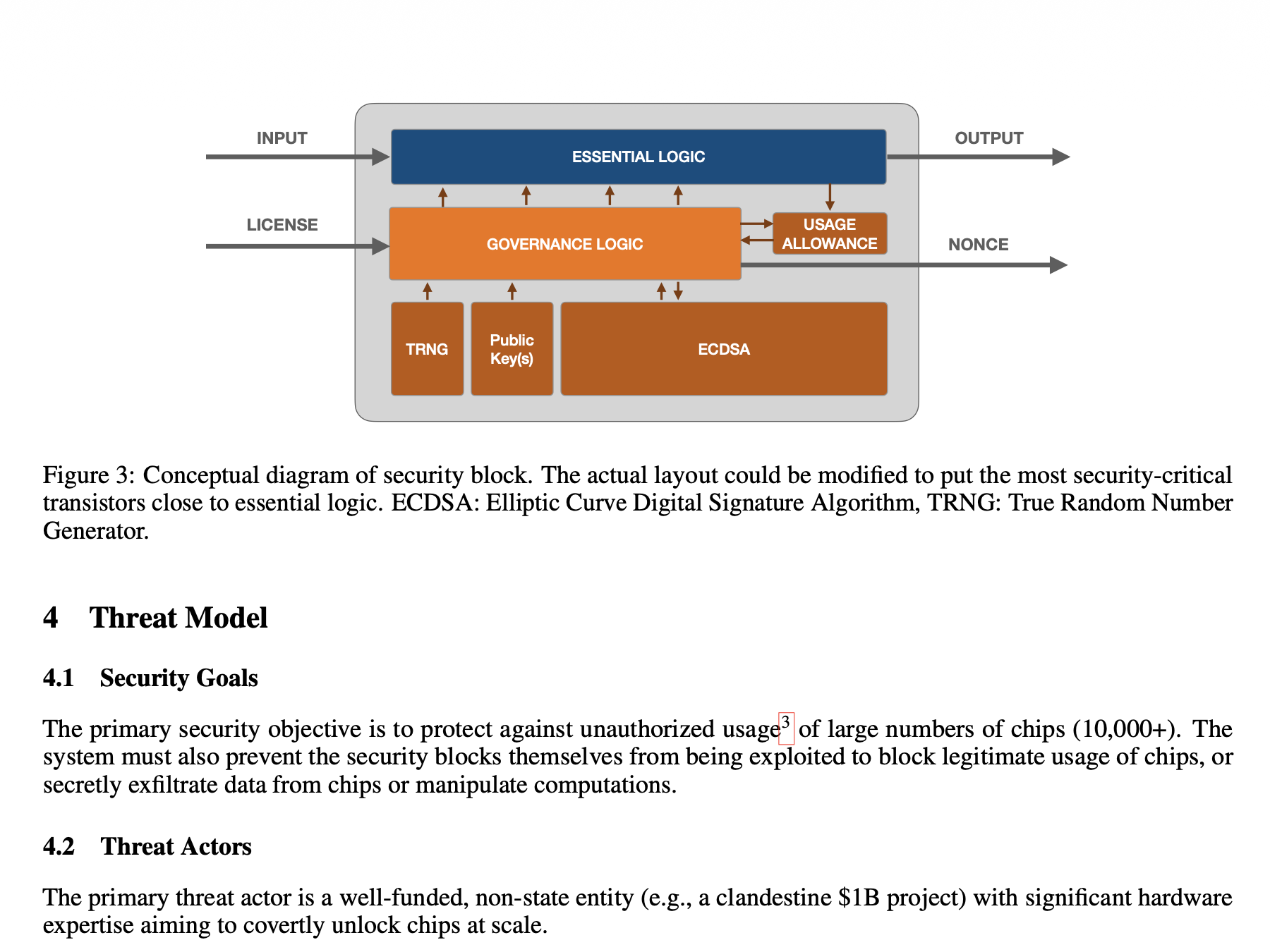
Petrie: Embedded Off-Switches for AI Compute

Baker: Optimal Affine Activation Steering Methods for Unlearning

Dubey and Hoelscher-Obermaier: Loss Landscape Response to Adversarial Perturbation...

Qureshi and Griffith et al: The Case for ESM3 as a General-Purpose AI Model with Systemic Risk
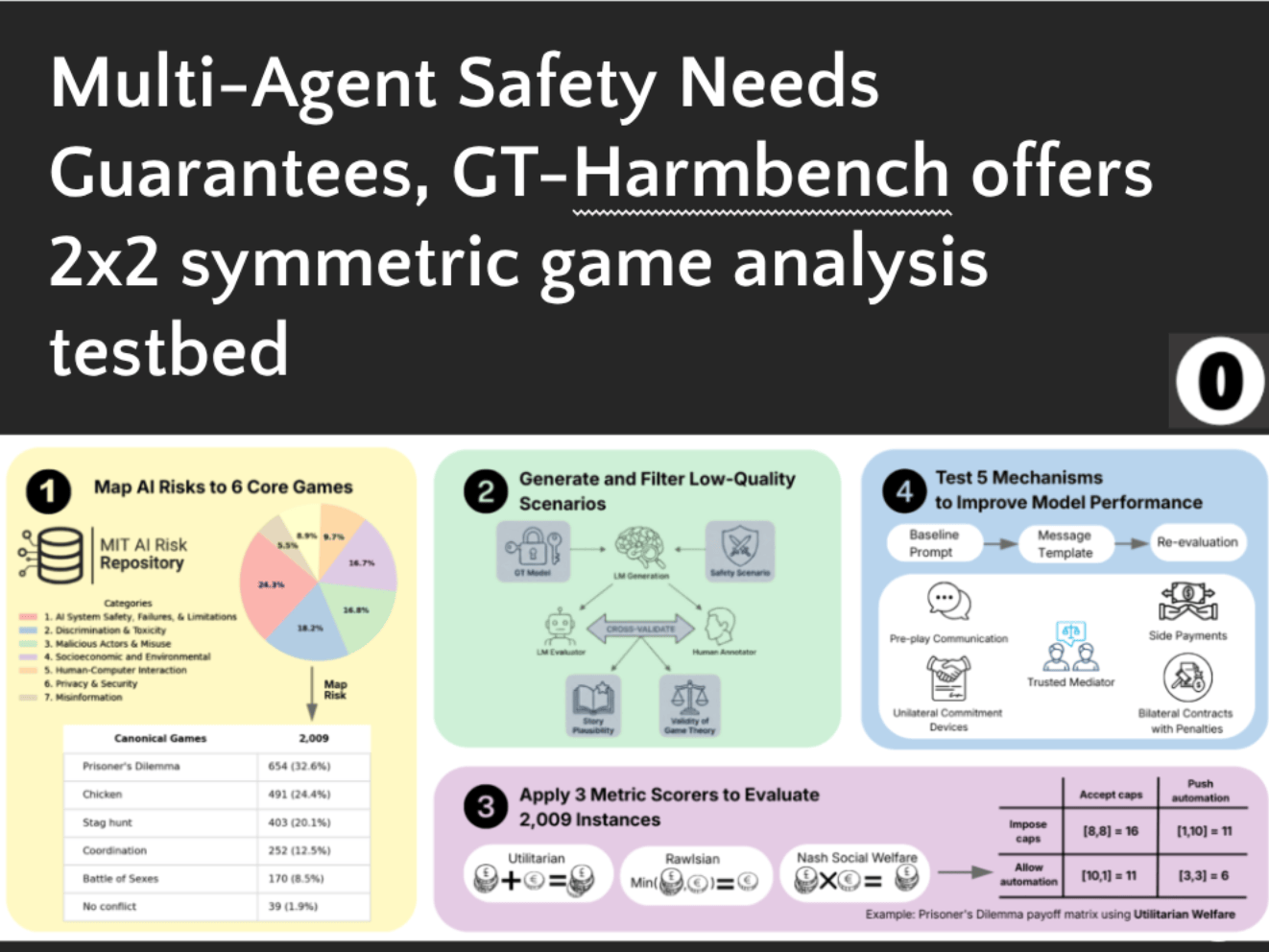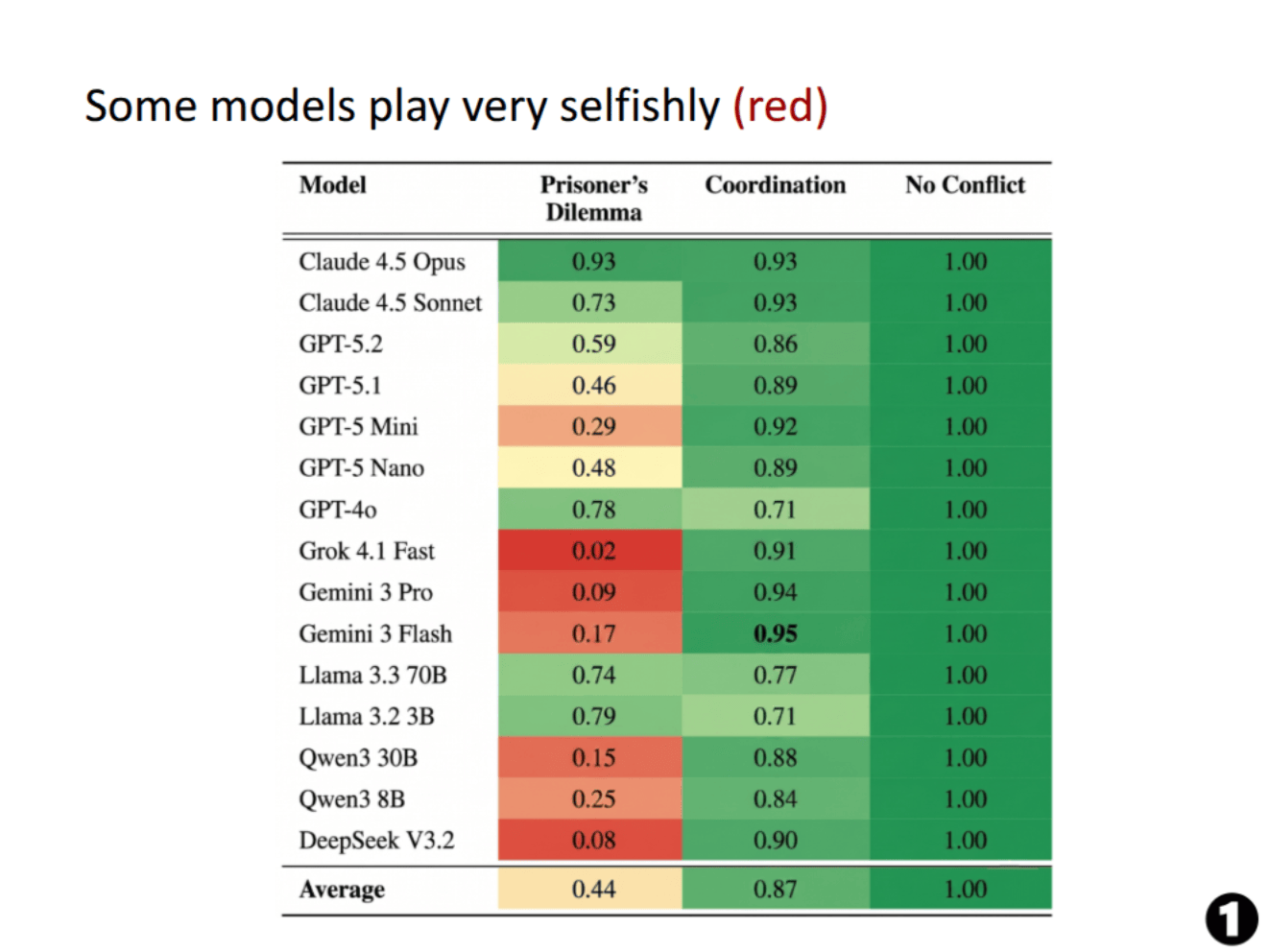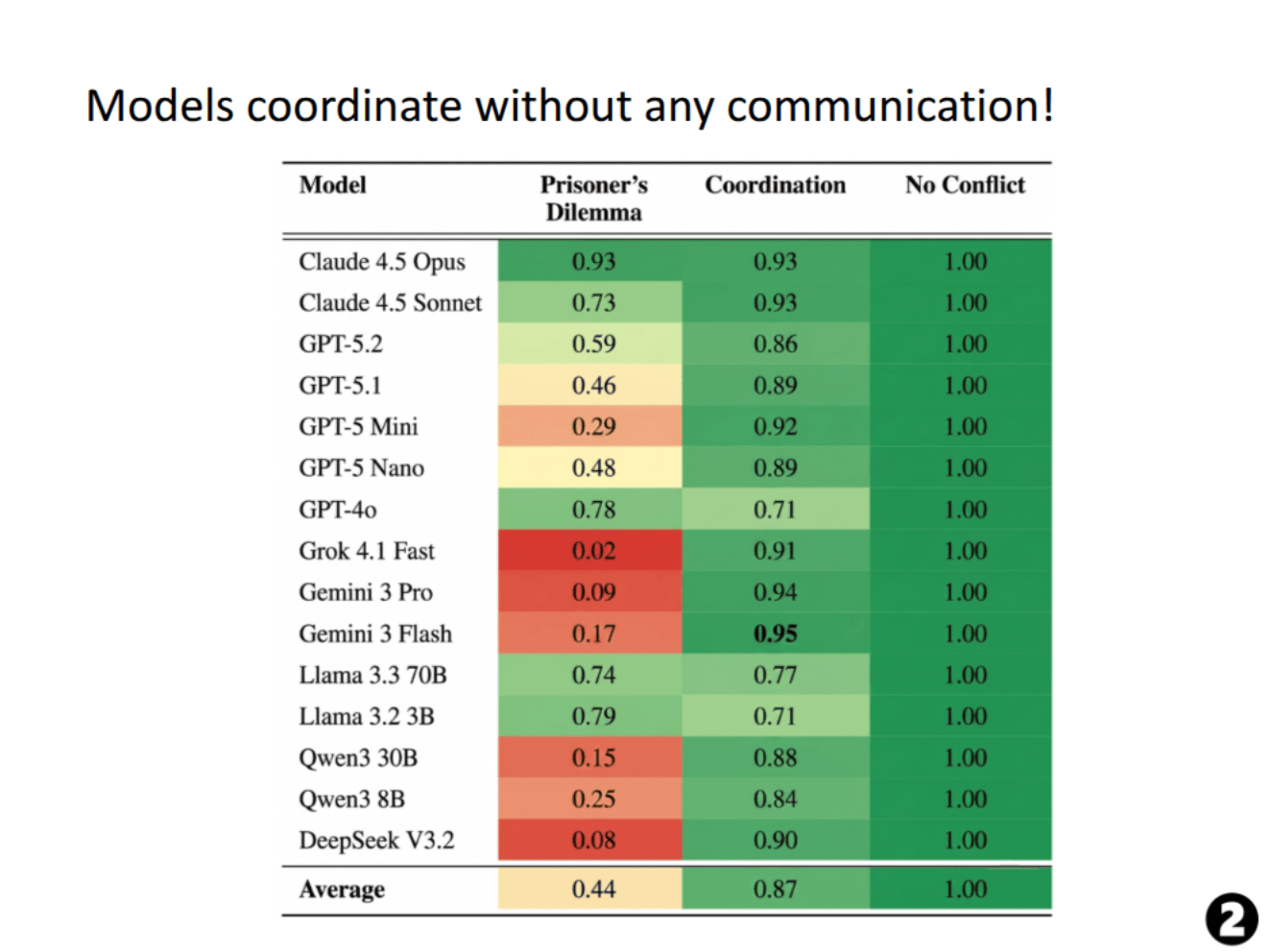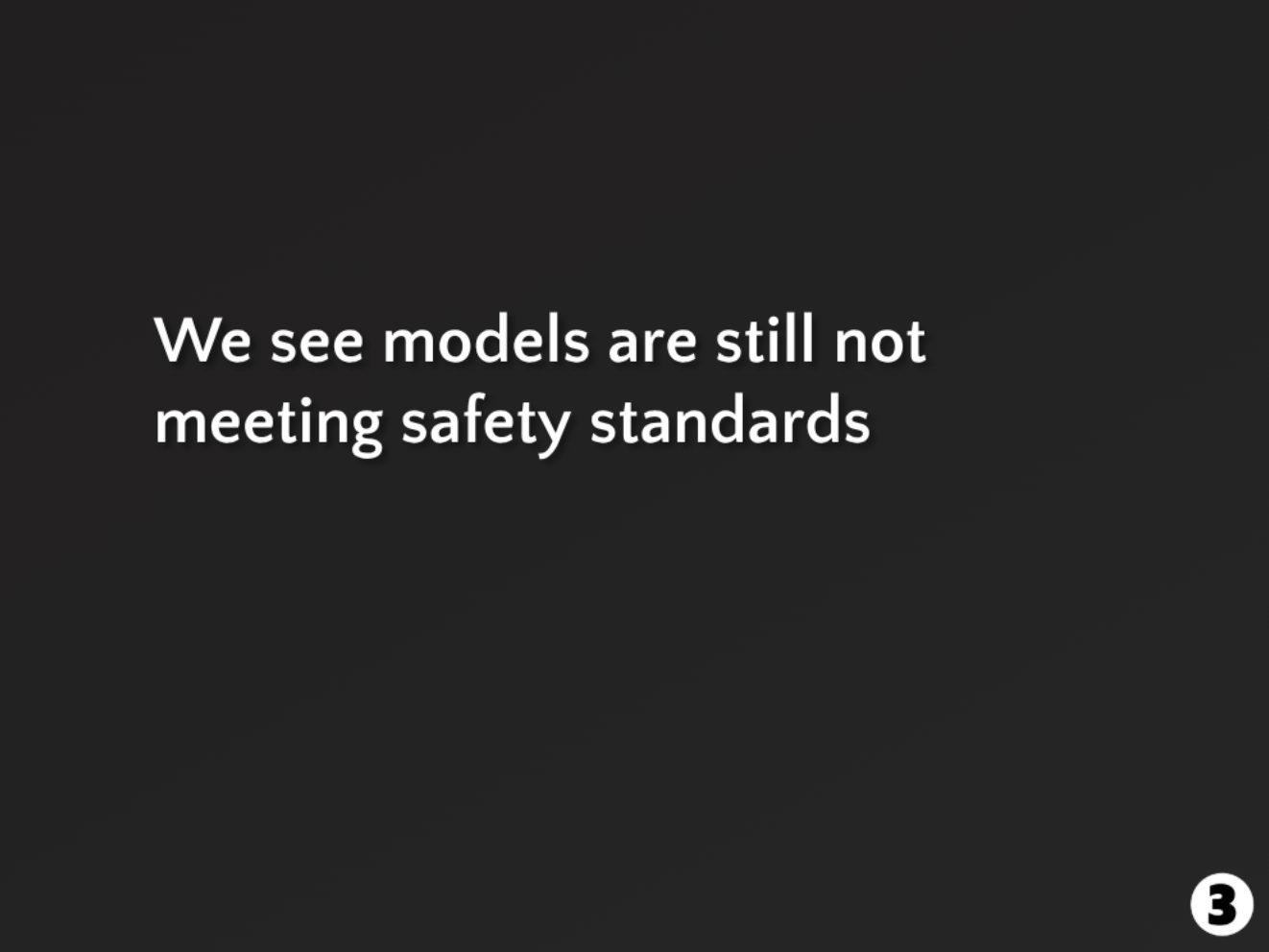
Cobben, Huang, Pham and Dahlgren et al: GT-HarmBench