Poster Board:
2
Oversight That Degrades:
Architectural Failure Modes in Human-LLM Control Structures
Brian Moriarty
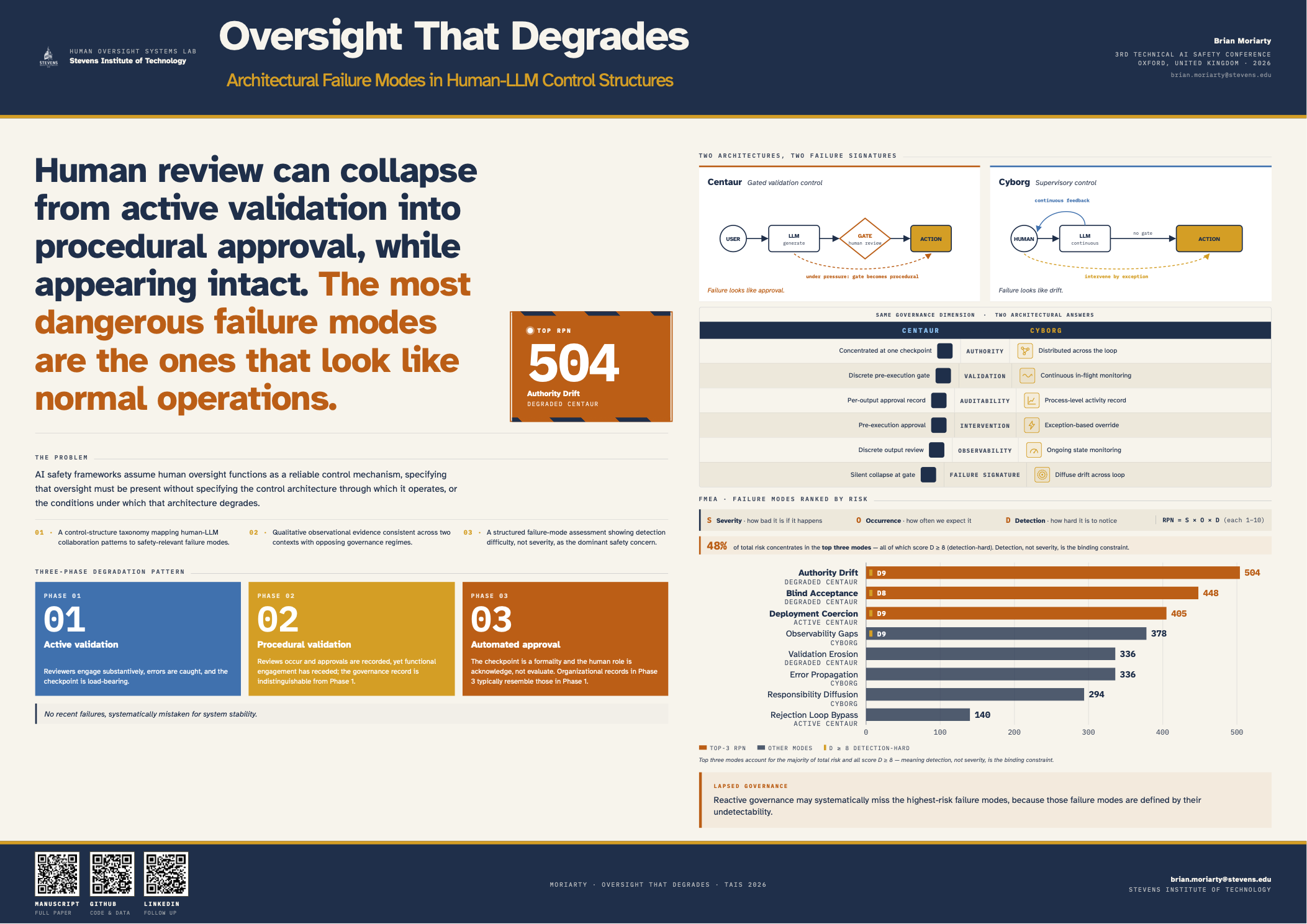
“Human review can collapse from active validation into procedural approval, while appearing intact. The most dangerous failure modes are the ones that look like normal operations.”
AI safety frameworks widely assume that human oversight provides a reliable control mechanism for AI systems. We present qualitative observational evidence, drawn from longitudinal practitioner contexts, consistent with a recurring degradation pattern under real-world conditions. The failure is not attributable to individual incompetence; oversight architectures appear to degrade structurally. Drawing on observations from academic and enterprise deployments of large language models (2022–2025), we identify a recurring pattern we term degraded oversight: human review collapses from active validation into procedural approval under time pressure, scale, and incentive misalignment, effectively transferring decision authority to the AI system while preserving the appearance of human control.
We formalize two distinct control architectures for human-LLM interaction, centaur (gated validation) and cyborg (supervisory control), and illustrate through FMEA-based prioritization that detection difficulty emerges as the dominant concern, outweighing failure severity in the prioritization: the most dangerous failure modes in this analysis are those where oversight has collapsed but the system appears to function normally. These observations are qualitative and practitioner-informed; we present them as a foundation for controlled empirical investigation rather than as generalizable findings in their own right.