
Poster Board:
6
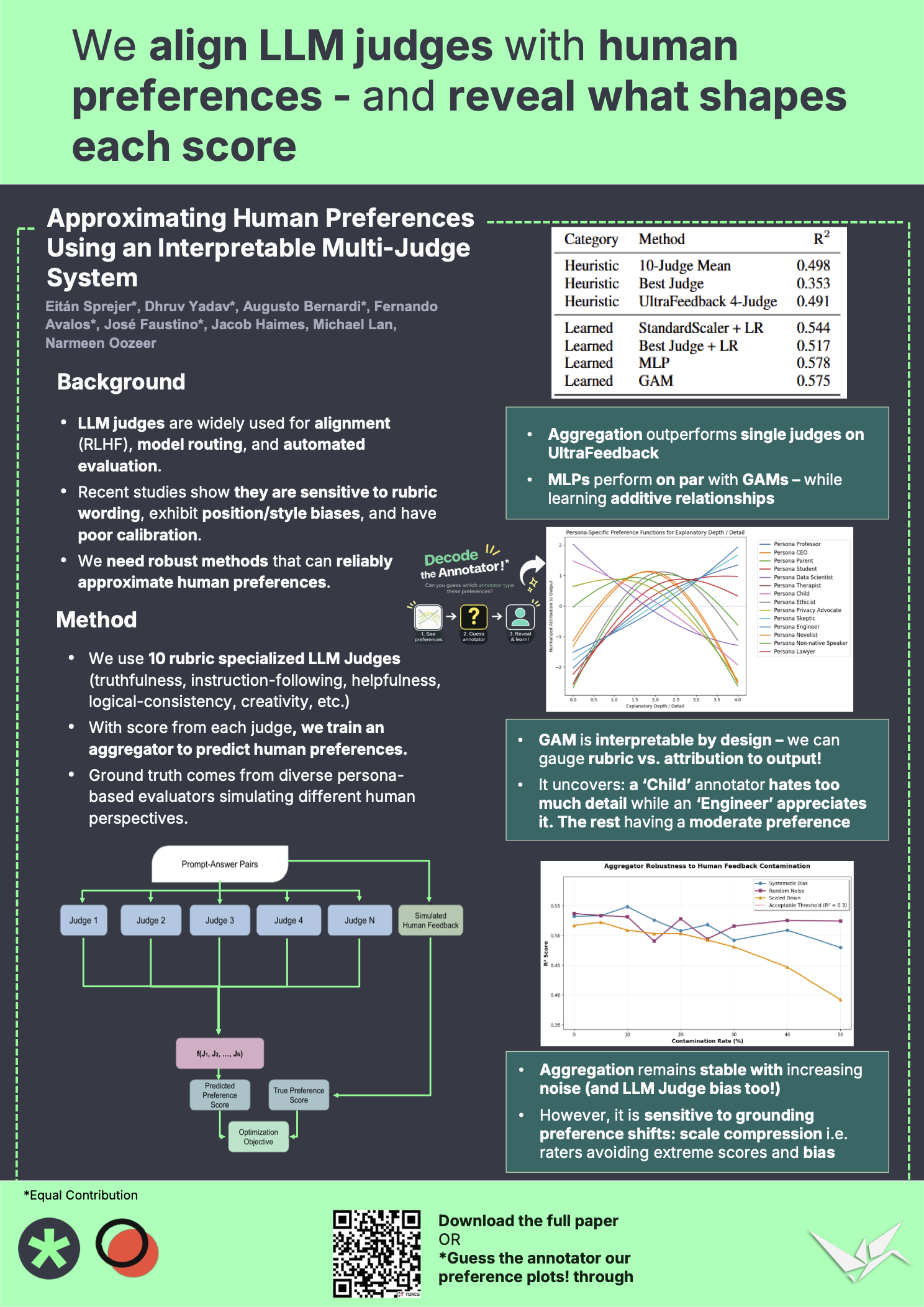
Approximating Human Preferences Using an Interpretable Multi-Judge System
Eitán Sprejer, Dhruv Yadav, Augusto M. Bernardi, Fernando Avalos, José Pedro B. de A. Faustino, Jacob Haimes, Michael Lan, Narmeen Fatimah Oozeer
“We align LLM judges with human preferences—and reveal what shapes each score.”
LLM-based judges are increasingly being used as proxies for human preference, such as in reward modeling for RLHF and construction of model routers. However, LLM judges are difficult to calibrate with human preferences, often suffering from rubric sensitivity, bias, and instability. This lack of transparency makes it difficult to diagnose failures, identify biased or redundant judges, and reliably improve multi-judge approaches, limiting trust and safe deployment in high-stakes settings. We introduce a novel, interpretable multijudge aggregator system that outperforms single judge approaches, and explicitly attributes the contributions of each individual judge by leveraging a lightweight Generalized Additive Model (GAM). To scale our approach in settings that lack pre-existing human preference data, we introduce a scalable method that employs multiple diverse personas for synthesizing preference labels. Our results show that our interpretable aggregator decomposes each persona’s preferences into a weighted mixture of judging features, revealing the criteria that drive the decisions of different annotators.