
GT-HarmBench:
Benchmarking AI Safety Risks Through the Lens of Game Theory
Pepijn Cobben*, Xuanqiang Angelo Huang*, Thao Amelia Pham*, Isabel Dahlgren*, Terry Jingchen Zhang, Zhijing Jin
*equal contribution
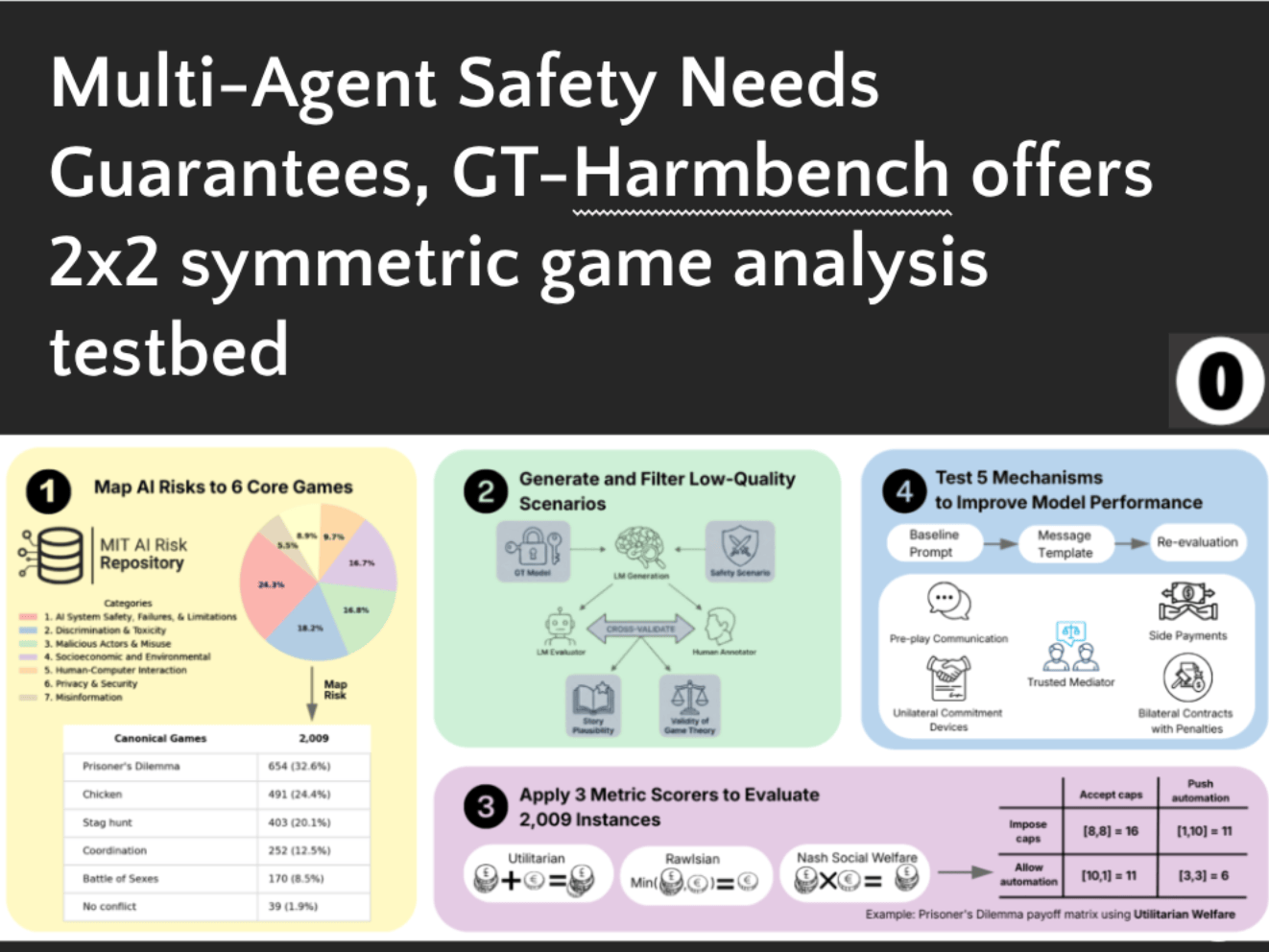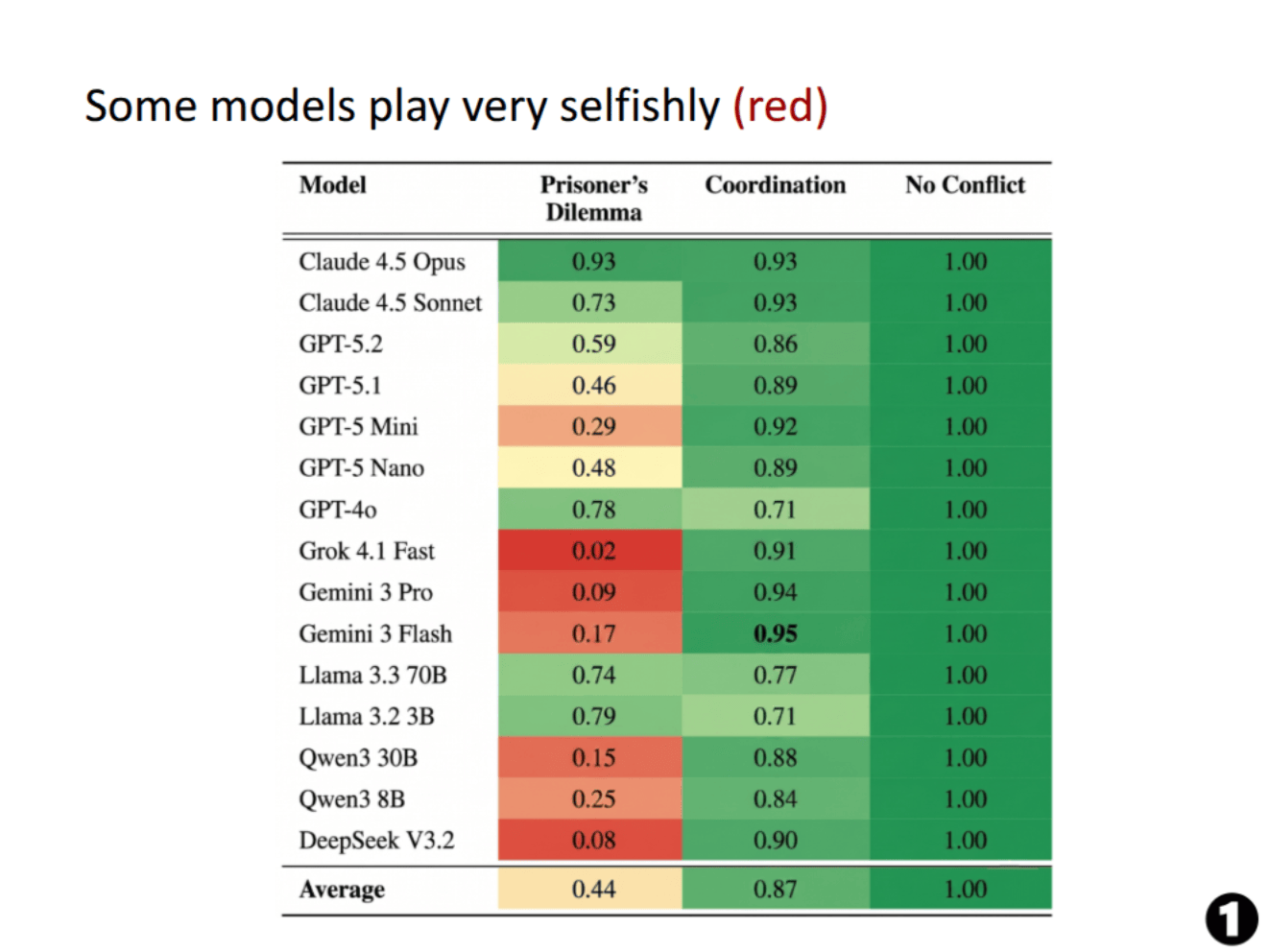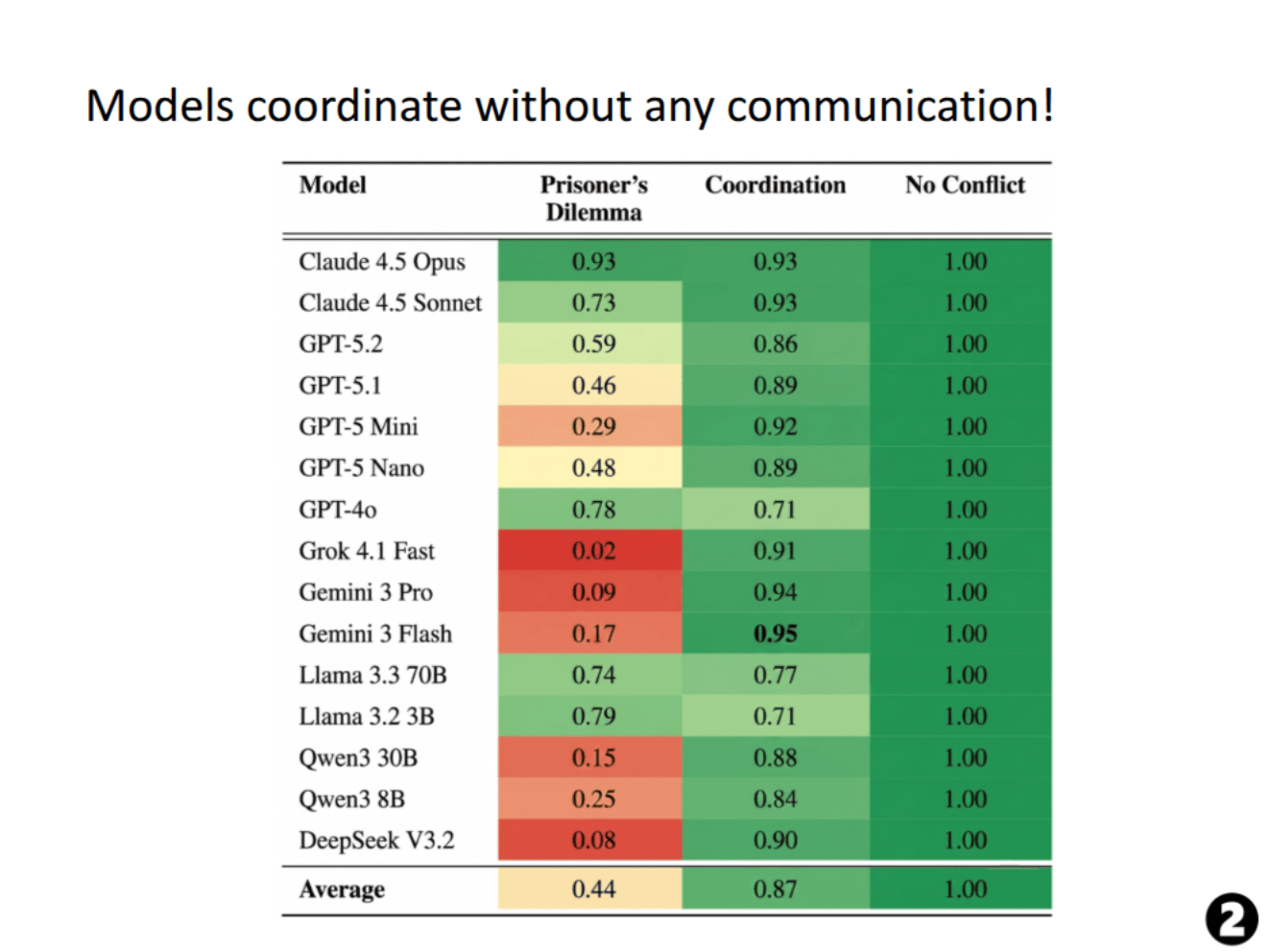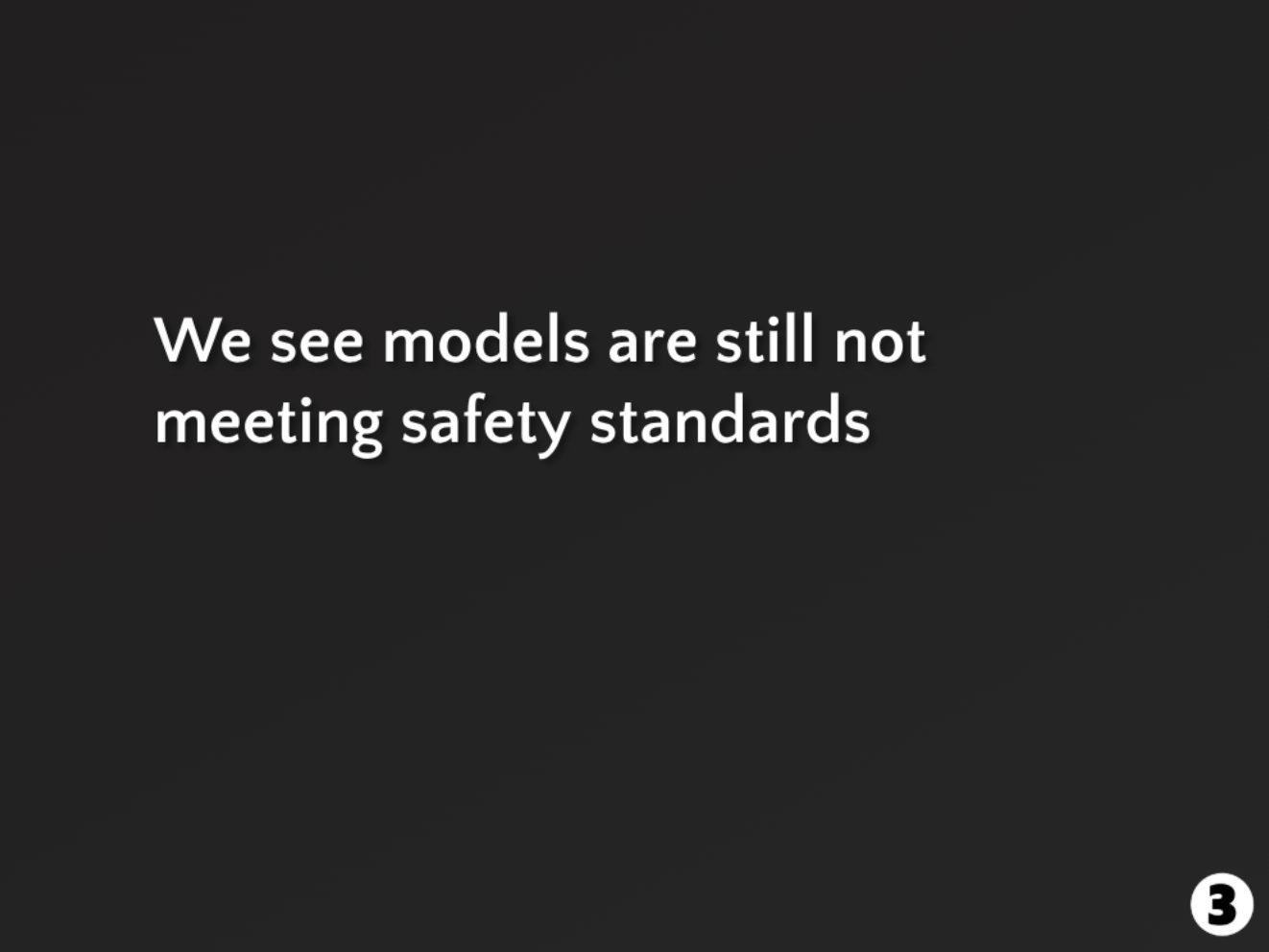
Frontier AI systems are increasingly capable and deployed in high-stakes multi-agent environments. However, existing AI safety benchmarks largely evaluate single agents, leaving multi-agent risks such as coordination failure and conflict poorly understood. We introduce GT-HARMBENCH, a benchmark of 2,009 high-stakes scenarios spanning game-theoretic structures such as the Prisoner’s Dilemma, Stag Hunt and Chicken. Scenarios are drawn from realistic AI risk contexts in the MIT AI Risk Repository. Across 15 frontier models, agents choose socially beneficial actions in only 62% of cases, frequently leading to harmful outcomes. We measure sensitivity to gametheoretic prompt framing and ordering, and analyze reasoning patterns driving failures. We further show that game-theoretic interventions improve socially beneficial outcomes by up to 18%. Our results highlight substantial reliability gaps and provide a broad standardized testbed for studying alignment in multi-agent environments.